@article{Churamani2025FCLSocRob,title={{Feature Aggregation with Latent Generative Replay for Federated Continual Learning of Socially Appropriate Robot Behaviours }},author={Churamani, Nikhil and Checker, Saksham and Dogan, Fethiye Irmak and Chiang, Hao-Tien Lewis and Gunes, Hatice},year={2025},}
Participant Perceptions of a Robotic Coach Conducting Positive Psychology Exercises: A Systematic Analysis
Minja Axelsson, Nikhil Churamani, Atahan Caldir, and Hatice Gunes
ACM Transactions on Human-Robot Interactions, 2025
@article{Axelsson2025PPI,author={Axelsson, Minja and Churamani, Nikhil and Caldir, Atahan and Gunes, Hatice},title={{Participant Perceptions of a Robotic Coach Conducting Positive Psychology Exercises: A Systematic Analysis}},journal={{ACM Transactions on Human-Robot Interactions}},year={2025},doi={10.1145/3711937},}
Continual Learning Should Move Beyond Incremental Classification
Join us for the second edition of the ”Dungeons, Neurons, and Dialogues: Social Interaction Dynamics in Contextual Games” (DnD-SIDC) workshop at HRI 2025! This engaging event will delve into the exciting intersection of human-robot interaction (HRI) and contextual games, exploring how embodied agents can enhance social dynamics within rich, narrative-driven environments. Participants will engage in thought-provoking discussions centered on empathy, trust, and cooperation as they navigate complex emotional landscapes in gaming scenarios.The workshop features a unique ”Quest for Solutions” activity, where attendees will collaborate in small groups to tackle specific challenges and design innovative pre-registration studies. This format fosters interdisciplinary collaboration among researchers, practitioners, and students from diverse fields, including robotics, psychology, game design, and AI.By leveraging the advancements in technology and the rising popularity of digital platforms, this workshop aims to inspire new ideas and partnerships that contribute to the sustainable development of social interactions in virtual spaces. Don’t miss this opportunity to explore cutting-edge research and contribute to the future of social computing in gaming! Join us and embark on a collaborative adventure in the realm of social interaction dynamics!
@inproceedings{Barros2025DnD,author={Barros, Pablo and Triglia, Laura and Churamani, Nikhil and Kerzel, Matthias},title={{Workshop Proposal: Dungeons, Neurons, and Dialogues 2 Edition: Social Interaction Dynamics in Contextual Games (DnD-SIDC)}},year={2025},publisher={IEEE Press},booktitle={Proceedings of the 2025 ACM/IEEE International Conference on Human-Robot Interaction},pages={1961–1963},numpages={3},keywords={affective computing, games and ai, human robot interaction},location={Melbourne, Australia},series={HRI '25},}
Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI): Overcoming Inequalities with Adaptation
Bahar Irfan, Nikhil Churamani, Michelle Zhao, Ali Ayub, and 1 more author
In Proceedings of the 2025 ACM/IEEE International Conference on Human-Robot Interaction, 2025
Global inequalities in access to essential resources such as education, healthcare, and technology continue to widen social and economic disparities, especially in underserved and underrepresented communities. The growing integration of foundation models and other machine learning systems in robots offers promising and personalized solutions that can adapt to various individuals, situations, and environments, potentially addressing some of these gaps. By learning from interactions and evolving with local conditions, these systems can provide individualized support, such as assisting older adults with daily tasks, aiding children with special needs in learning environments, or empowering people with disabilities to live more independently. Building trust and fostering collaboration between humans and robots will help ensure that these systems meet the unique needs of all individuals, especially within long-term human-robot interaction (HRI). With this year’s theme of "Overcoming Inequalities with Adaptation”, in line with the overall theme of the conference "Robots for a Sustainable World”, the fifth edition of the "Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI)” workshop aims to bring together insights across diverse disciplines, exploring how continually evolving robots can effectively operate in diverse environments, promoting greater equity, inclusivity, and empowerment for individuals and communities. The workshop aims to facilitate collaborations across diverse scientific perspectives through a keynote presentation, panel discussions, and in-depth discussions on the contributed talks, attempting to shape a more sustainable and equitable future through adaptive advancements in long-term HRI.
@inproceedings{Irfan2025LEAPHRI,author={Irfan, Bahar and Churamani, Nikhil and Zhao, Michelle and Ayub, Ali and Rossi, Silvia},title={{Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI): Overcoming Inequalities with Adaptation}},year={2025},publisher={IEEE Press},booktitle={Proceedings of the 2025 ACM/IEEE International Conference on Human-Robot Interaction},pages={1970–1972},numpages={3},keywords={adaptation, continual learning, human-robot interaction (hri), inequalities, lifelong learning, long-term hri, personalization, user modeling, workshop},location={Melbourne, Australia},series={HRI '25},}
Graph Neural Networks for Surgical Scene Segmentation
Yihan Li, Nikhil Churamani, Maria Robu, Imanol Luengo, and 1 more author
@article{Li2025GNN,title={{Graph Neural Networks for Surgical Scene Segmentation}},author={Li, Yihan and Churamani, Nikhil and Robu, Maria and Luengo, Imanol and Stoyanov, Danail},year={2025},}
2024
Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI): Open-World Learning
Bahar Irfan, Mariacarla Staffa, Andreea Bobu, and Nikhil Churamani
In Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, 2024
The complex and largely unstructured nature of real-world situations makes it challenging for conventional closed-world robot learning solutions to adapt to such interaction dynamics. These challenges become particularly pronounced in long-term interactions where robots need to go beyond their past learning to continuously evolve with changing environment settings and personalize towards individual user behaviors. In contrast, open-world learning embraces the complexity and unpredictability of the real world, enabling robots to be "lifelong learners" that continuously acquire new knowledge and navigate novel challenges, making them more context-aware while intuitively engaging the users. Adopting the theme of "open-world learning", the fourth edition of the "Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI)" workshop seeks to bring together interdisciplinary perspectives on real-world applications in human-robot interaction (HRI), including education, rehabilitation, elderly care, service, and companionship. The goal of the workshop is to foster collaboration and understanding across diverse scientific communities through invited keynote presentations and in-depth discussions facilitated by contributed talks, a break-out session, and a debate.
@inproceedings{Irfan2024LEAPHRI,author={Irfan, Bahar and Staffa, Mariacarla and Bobu, Andreea and Churamani, Nikhil},title={Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI): Open-World Learning},year={2024},isbn={9798400703232},publisher={Association for Computing Machinery},address={New York, NY, USA},doi={10.1145/3610978.3638159},booktitle={Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction},pages={1323–1325},numpages={3},keywords={adaptation, continual learning, human-robot interaction, lifelong learning, open-world learning, personalization, workshop},location={Boulder, CO, USA},series={HRI '24},}
Causal-HRI: Causal Learning for Human-Robot Interaction
Jiaee Cheong, Nikhil Churamani, Luke Guerdan, Tabitha Edith Lee, and 2 more authors
In Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, 2024
Real-world Human-Robot Interaction (HRI) requires robots to adeptly perceive and understand the dynamic human-centred environments in which they operate. Recent decades have seen remarkable advancements that have endowed robots with exceptional perception capabilities. The first workshop on "Causal-HRI: Causal Learning for Human-Robot Interaction" aims to bring together research perspectives from Causal Discovery and Inference and Causal Learning, in general, to real-world HRI applications. The objective of this workshop is to explore strategies that will not only embed robots with capabilities to discover cause-and-effect relationships from observations, allowing them to generalise to unseen interaction settings, but also to enable users to understand robot behaviours, moving beyond the ’black-box’ models used by these robots. This workshop aims to facilitate an exchange of views through invited keynote presentations, contributed talks, group discussions and poster sessions, encouraging collaborations across diverse scientific communities. The theme of HRI 2024, "HRI in the real world," will inform the overarching theme of this workshop, encouraging discussions on HRI theories, methods, designs and studies focused on leveraging Causal Learning for enhancing real-world HRI.
@inproceedings{Cheong2024CausalHRI,author={Cheong, Jiaee and Churamani, Nikhil and Guerdan, Luke and Lee, Tabitha Edith and Han, Zhao and Gunes, Hatice},title={Causal-HRI: Causal Learning for Human-Robot Interaction},year={2024},isbn={9798400703232},publisher={Association for Computing Machinery},address={New York, NY, USA},doi={10.1145/3610978.3638157},booktitle={Companion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction},pages={1311–1313},numpages={3},keywords={causal discovery, causal inference, causal learning, cognitive robotics, human-robot interaction, intelligent agents, robotics},location={Boulder, CO, USA},series={HRI '24},}
Federated Learning of Socially Appropriate Agent Behaviours in Simulated Home Environments
Saksham Checker, Nikhil Churamani, and Hatice Gunes
In Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 19th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2024
@inproceedings{Checker2024FL,title={{Federated Learning of Socially Appropriate Agent Behaviours in Simulated Home Environments}},author={Checker, Saksham and Churamani, Nikhil and Gunes, Hatice},booktitle={{Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 19th ACM/IEEE International Conference on Human-Robot Interaction (HRI)}},year={2024},}
2023
Latent Generative Replay for Resource-Efficient Continual Learning of Facial Expressions
Samuil Stoychev, Nikhil Churamani, and Hatice Gunes
In 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), 2023
@inproceedings{Stoychev2023LGR,author={Stoychev, Samuil and Churamani, Nikhil and Gunes, Hatice},booktitle={2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG)},title={Latent Generative Replay for Resource-Efficient Continual Learning of Facial Expressions},year={2023},pages={1-8},doi={10.1109/FG57933.2023.10042642},}
Towards Causal Replay for Knowledge Rehearsal in Continual Learning
Nikhil Churamani, Jiaee Cheong, Sinan Kalkan, and Hatice Gunes
In Proceedings of The First AAAI Bridge Program on Continual Causality, 2023
Given the challenges associated with the real-world deployment of Machine Learning (ML) models, especially towards efficiently integrating novel information on-the-go, both Continual Learning (CL) and Causality have been proposed and investigated individually as potent solutions. Despite their complimentary nature, the bridge between them is still largely unexplored. In this work, we focus on causality to improve the learning and knowledge preservation capabilities of CL models. In particular, positing Causal Replay for knowledge rehearsal, we discuss how CL-based models can benefit from causal interventions towards improving their ability to replay past knowledge in order to mitigate forgetting.
@inproceedings{pmlr-v208-churamani23a,title={Towards Causal Replay for Knowledge Rehearsal in Continual Learning},author={Churamani, Nikhil and Cheong, Jiaee and Kalkan, Sinan and Gunes, Hatice},booktitle={Proceedings of The First AAAI Bridge Program on Continual Causality},pages={63--70},year={2023},editor={Mundt, Martin and Cooper, Keiland W. and Dhami, Devendra Singh and Ribeiro, Adéle and Smith, James Seale and Bellot, Alexis and Hayes, Tyler},volume={208},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Affective Computing for Human-Robot Interaction Research: Four Critical Lessons for the Hitchhiker
Hatice Gunes, and Nikhil Churamani
In The 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2023
@inproceedings{Gunes2023Affective,title={Affective Computing for Human-Robot Interaction Research: Four Critical Lessons for the Hitchhiker},author={Gunes, Hatice and Churamani, Nikhil},booktitle={The 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)},year={2023},pages={1565-1572},doi={10.1109/RO-MAN57019.2023.10309450},}
Continual Facial Expression Recognition: A Benchmark
Nikhil Churamani, Tolga Dimlioglu, German I. Parisi, and Hatice Gunes
@article{Churamani2023ConFER,title={Continual Facial Expression Recognition: A Benchmark},author={Churamani, Nikhil and Dimlioglu, Tolga and Parisi, German I. and Gunes, Hatice},year={2023},}
2022
CVPR 2020 continual learning in computer vision competition: Approaches, results, current challenges and future directions
Vincenzo Lomonaco, Lorenzo Pellegrini, Pau Rodriguez, Massimo Caccia, and 11 more authors
In the last few years, we have witnessed a renewed and fast-growing interest in continual learning with deep neural networks with the shared objective of making current AI systems more adaptive, efficient and autonomous. However, despite the significant and undoubted progress of the field in addressing the issue of catastrophic forgetting, benchmarking different continual learning approaches is a difficult task by itself. In fact, given the proliferation of different settings, training and evaluation protocols, metrics and nomenclature, it is often tricky to properly characterize a continual learning algorithm, relate it to other solutions and gauge its real-world applicability. The first Continual Learning in Computer Vision challenge held at CVPR in 2020 has been one of the first opportunities to evaluate different continual learning algorithms on a common hardware with a large set of shared evaluation metrics and 3 different settings based on the realistic CORe50 video benchmark. In this paper, we report the main results of the competition, which counted more than 79 teams registered and 11 finalists. We also summarize the winning approaches, current challenges and future research directions.
@article{LOMONACO2022103635,title={CVPR 2020 continual learning in computer vision competition: Approaches, results, current challenges and future directions},journal={Artificial Intelligence},volume={303},pages={103635},year={2022},issn={0004-3702},doi={https://doi.org/10.1016/j.artint.2021.103635},author={Lomonaco, Vincenzo and Pellegrini, Lorenzo and Rodriguez, Pau and Caccia, Massimo and She, Qi and Chen, Yu and Jodelet, Quentin and Wang, Ruiping and Mai, Zheda and Vazquez, David and Parisi, German I. and Churamani, Nikhil and Pickett, Marc and Laradji, Issam and Maltoni, Davide},keywords={Continual learning, Lifelong learning, Incremental learning, Challenge, Computer vision},}
Affect-Driven Learning of Robot Behaviour for Collaborative Human-Robot Interactions
Nikhil Churamani, Pablo Barros, Hatice Gunes, and Stefan Wermter
Collaborative interactions require social robots to share the users’ perspective on the interactions and adapt to the dynamics of their affective behaviour. Yet, current approaches for affective behaviour generation in robots focus on instantaneous perception to generate a one-to-one mapping between observed human expressions and static robot actions. In this paper, we propose a novel framework for affect-driven behaviour generation in social robots. The framework consists of (i) a hybrid neural model for evaluating facial expressions and speech of the users, forming intrinsic affective representations in the robot, (ii) an Affective Core, that employs self-organising neural models to embed behavioural traits like patience and emotional actuation that modulate the robot’s affective appraisal, and (iii) a Reinforcement Learning model that uses the robot’s appraisal to learn interaction behaviour. We investigate the effect of modelling different affective core dispositions on the affective appraisal and use this affective appraisal as the motivation to generate robot behaviours. For evaluation, we conduct a user study (n = 31) where the NICO robot acts as a proposer in the Ultimatum Game. The effect of the robot’s affective core on its negotiation strategy is witnessed by participants, who rank a patient robot with high emotional actuation higher on persistence, while an impatient robot with low emotional actuation is rated higher on its generosity and altruistic behaviour.
@article{Churamani2022AffCore,author={Churamani, Nikhil and Barros, Pablo and Gunes, Hatice and Wermter, Stefan},title={Affect-Driven Learning of Robot Behaviour for Collaborative Human-Robot Interactions},year={2022},publisher={Frontiers Media {SA}},journal={Frontiers in Robotics and {AI}},volume={9},doi={10.3389/frobt.2022.717193},issn={2296-9144},}
Learning Socially Appropriate Robo-Waiter Behaviours through Real-Time User Feedback
Emily McQuillin, Nikhil Churamani, and Hatice Gunes
In Proceedings of the 2022 ACM/IEEE International Conference on Human-Robot Interaction, 2022
Current Humanoid Service Robot (HSR) behaviours mainly rely on static models that cannot adapt dynamically to meet individual customer attitudes and preferences. In this work, we focus on empowering HSRs with adaptive feedback mechanisms driven by either implicit reward, by estimating facial affect, or explicit reward, by incorporating verbal responses of the human ’customer’. To achieve this, we first create a custom dataset, annotated using crowd-sourced labels, to learn appropriate approach (positioning and movement) behaviours for a Robo-waiter. This dataset is used to pre-train a Reinforcement Learning (RL) agent to learn behaviours deemed socially appropriate for the robo-waiter. This model is later extended to include separate implicit and explicit reward mechanisms to allow for interactive learning and adaptation from user social feedback. We present a within-subjects Human-Robot Interaction (HRI) study with 21 participants implementing interactions between the robo-waiter and human customers implementing the above-mentioned model variations. Our results show that both explicit and implicit adaptation mechanisms enabled the adaptive robo-waiter to be rated as more enjoyable and sociable, and its positioning relative to the participants as more appropriate compared to using the pre-trained model or a randomised control implementation.
@inproceedings{McQuillin2022RoboWaiter,author={McQuillin, Emily and Churamani, Nikhil and Gunes, Hatice},title={Learning Socially Appropriate Robo-Waiter Behaviours through Real-Time User Feedback},year={2022},publisher={IEEE Press},booktitle={Proceedings of the 2022 ACM/IEEE International Conference on Human-Robot Interaction},pages={541–550},numpages={10},keywords={facial affect, implicit feedback, explicit feedback, reinforcement learning, humanoid robo-waiter},location={Sapporo, Hokkaido, Japan},series={HRI '22},doi={10.5555/3523760.3523831},}
Domain-Incremental Continual Learning for Mitigating Bias in Facial Expression and Action Unit Recognition
@article{Churamani2022DICL4Bias,author={Churamani, Nikhil and Kara, Ozgur and Gunes, Hatice},journal={{IEEE Transactions on Affective Computing}},title={{Domain-Incremental Continual Learning for Mitigating Bias in Facial Expression and Action Unit Recognition}},year={2022},pages={1-15},doi={10.1109/TAFFC.2022.3181033},}
Continual Learning for Affective Robotics: A Proof of Concept for Wellbeing
Nikhil Churamani, Minja Axelsson, Atahan Çaldır, and Hatice Gunes
In 2022 10th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), 2022
@inproceedings{Churamani2022CL4HRI,author={Churamani, Nikhil and Axelsson, Minja and Çaldır, Atahan and Gunes, Hatice},booktitle={2022 10th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW)},title={Continual Learning for Affective Robotics: A Proof of Concept for Wellbeing},year={2022},volume={},number={},pages={1-8},doi={10.1109/ACIIW57231.2022.10086005},}
2021
Towards Fair Affective Robotics: Continual Learning for Mitigating Bias in Facial Expression and Action Unit Recognition
Ozgur Kara, Nikhil Churamani, and Hatice Gunes
In Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 16th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2021
@inproceedings{Kara2021Towards,title={{Towards Fair Affective Robotics: Continual Learning for Mitigating Bias in Facial Expression and Action Unit Recognition}},author={Kara, Ozgur and Churamani, Nikhil and Gunes, Hatice},booktitle={{Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 16th ACM/IEEE International Conference on Human-Robot Interaction (HRI)}},year={2021},}
Teleoperated Robot Coaching for Mindfulness Training: A Longitudinal Study
Indu P. Bodala, Nikhil Churamani, and Hatice Gunes
In 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN), 2021
Finalist for the RSJ/KROS Distinguished Interdisciplinary Research Award
@inproceedings{Bodala2021Teleoperated,author={Bodala, Indu P. and Churamani, Nikhil and Gunes, Hatice},booktitle={2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN)},title={Teleoperated Robot Coaching for Mindfulness Training: A Longitudinal Study},year={2021},volume={},number={},pages={939-944},note={Finalist for the RSJ/KROS Distinguished Interdisciplinary Research Award},doi={10.1109/RO-MAN50785.2021.9515371},}
AULA-Caps: Lifecycle-Aware Capsule Networks for Spatio-Temporal Analysis of Facial Actions
Nikhil Churamani, Sinan Kalkan, and Hatice Gunes
In 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), 2021
@inproceedings{Churamani2021AULACaps,author={Churamani, Nikhil and Kalkan, Sinan and Gunes, Hatice},booktitle={2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021)},title={{AULA-Caps: Lifecycle-Aware Capsule Networks for Spatio-Temporal Analysis of Facial Actions}},year={2021},pages={01-08},doi={10.1109/FG52635.2021.9666978},}
2020
The FaceChannel: A Light-weight Deep Neural Network for Facial Expression Recognition
Pablo Barros, Nikhil Churamani, and Alessandra Sciutti
In 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), 2020
@inproceedings{Barros2020FaceChannel,author={Barros, Pablo and Churamani, Nikhil and Sciutti, Alessandra},booktitle={2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020)},title={{The FaceChannel: A Light-weight Deep Neural Network for Facial Expression Recognition}},year={2020},pages={652-656},doi={10.1109/FG47880.2020.00070},}
Continual Learning for Affective Computing
Nikhil Churamani
In Doctoral Consortium Proceedings of the 15th International Conference on Automatic Face and Gesture Recognition (FG), 2020
@inproceedings{Churamani2020CLAC,author={Churamani, Nikhil},title={{Continual Learning for Affective Computing}},booktitle={Doctoral Consortium Proceedings of the 15th International Conference on Automatic Face and Gesture Recognition (FG)},year={2020},publisher={IEEE},note={{Best Doctoral Consortium Award}},}
CLIFER: Continual Learning with Imagination for Facial Expression Recognition
Nikhil Churamani, and Hatice Gunes
In Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2020
@inproceedings{Churamani2020CLIFER,author={Churamani, Nikhil and Gunes, Hatice},booktitle={Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG)},title={{CLIFER: Continual Learning with Imagination for Facial Expression Recognition}},year={2020},publisher={IEEE},pages={322--328},doi={10.1109/FG47880.2020.00110},}
The FaceChannel: A Fast and Furious Deep Neural Network for Facial Expression Recognition
Pablo Barros, Nikhil Churamani, and Alessandra Sciutti
@article{Barros2020FaceChannelSN,doi={10.1007/s42979-020-00325-6},url={https://doi.org/10.1007/s42979-020-00325-6},year={2020},publisher={Springer Science and Business Media {LLC}},volume={1},number={6},author={Barros, Pablo and Churamani, Nikhil and Sciutti, Alessandra},title={The {FaceChannel}: A Fast and Furious Deep Neural Network for Facial Expression Recognition},journal={{SN} Computer Science},}
Creating a Robot Coach for Mindfulness and Wellbeing: A Longitudinal Study
Indu P. Bodala, Nikhil Churamani, and Hatice Gunes
@article{Bodala2020creating,title={Creating a Robot Coach for Mindfulness and Wellbeing: A Longitudinal Study},author={Bodala, Indu P. and Churamani, Nikhil and Gunes, Hatice},year={2020},note={arXiv 2006.05289},}
Continual Learning for Affective Robotics: Why, What and How?
Nikhil Churamani, Sinan Kalkan, and Hatice Gunes
In 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2020
@inproceedings{Churamani2020CL4AR,author={Churamani, Nikhil and Kalkan, Sinan and Gunes, Hatice},booktitle={2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)},title={{Continual Learning for Affective Robotics: Why, What and How?}},year={2020},pages={425-431},doi={10.1109/RO-MAN47096.2020.9223564},}
2019
The OMG-Empathy Dataset: Evaluating the Impact of Affective Behavior in Storytelling
Pablo Barros, Nikhil Churamani, Angelica Lim, and Stefan Wermter
In Proceedings of the 8th International Conference on Affective Computing and Intelligent Interaction (ACII), 2019
@inproceedings{Barros2019OMGEmpathy,author={Barros, Pablo and Churamani, Nikhil and Lim, Angelica and Wermter, Stefan},booktitle={Proceedings of the 8th International Conference on Affective Computing and Intelligent Interaction (ACII)},title={{The OMG-Empathy Dataset: Evaluating the Impact of Affective Behavior in Storytelling}},year={2019},moth={September},organization={IEEE},pages={1--7},location={Cambridge, UK},doi={10.1109/ACII.2019.8925530},}
2018
An Affective Robot Companion for Assisting the Elderly in a Cognitive Game Scenario
Nikhil Churamani, Alexander Sutherland, and Pablo Barros
In Proceedings of the Workshop on Intelligent Assistive Computing, IEEE World Congress on Computational Intelligence (WCCI) 2018, Jul 2018
@inproceedings{Churamani2018AnAffective,author={Churamani, Nikhil and Sutherland, Alexander and Barros, Pablo},title={An Affective Robot Companion for Assisting the Elderly in a Cognitive Game Scenario},booktitle={Proceedings of the Workshop on Intelligent Assistive Computing, IEEE World Congress on Computational Intelligence (WCCI) 2018},month=jul,year={2018},organisation={IEEE},}
The OMG-Emotion Behavior Dataset
Pablo Barros, Nikhil Churamani, Egor Lakomkin, Henrique Sequeira, and 2 more authors
In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Jul 2018
@inproceedings{Barros2018OMGEmotion,author={Barros, Pablo and Churamani, Nikhil and Lakomkin, Egor and Sequeira, Henrique and Sutherland, Alexander and Wermter, Stefan},booktitle={Proceedings of the International Joint Conference on Neural Networks (IJCNN)},title={{The OMG-Emotion Behavior Dataset}},year={2018},moth={July},organization={IEEE},pages={1408--1414},location={Rio de Janeiro, Brazil},keywords={Videos;Emotion recognition;Tools;YouTube;Context modeling;Neural networks;Sentiment analysis},doi={10.1109/IJCNN.2018.8489099},issn={2161-4407},}
Learning Empathy-Driven Emotion Expression using Affective Modulations
Nikhil Churamani, Pablo Barros, Erik Strahl, and Stefan Wermter
In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Jul 2018
@inproceedings{Churamani2018Learning,author={Churamani, Nikhil and Barros, Pablo and Strahl, Erik and Wermter, Stefan},booktitle={Proceedings of the International Joint Conference on Neural Networks (IJCNN)},title={Learning Empathy-Driven Emotion Expression using Affective Modulations},year={2018},moth={July},organization={IEEE},pages={1400--1407},location={Rio de Janeiro, Brazil},keywords={Mood;Adaptation models;Neurons;Robot sensing systems;Convolution;Emotion recognition},doi={10.1109/IJCNN.2018.8489158},issn={2161-4407},url={http://www.doi.org/10.1109/IJCNN.2018.8489158},}
2017
Teaching emotion expressions to a human companion robot using deep neural architectures
Nikhil Churamani, Matthias Kerzel, Erik Strahl, Pablo Barros, and 1 more author
In 2017 International Joint Conference on Neural Networks (IJCNN), May 2017
@inproceedings{CKSBW2017Teaching,author={Churamani, Nikhil and Kerzel, Matthias and Strahl, Erik and Barros, Pablo and Wermter, Stefan},booktitle={2017 International Joint Conference on Neural Networks (IJCNN)},title={Teaching emotion expressions to a human companion robot using deep neural architectures},year={2017},pages={627-634},keywords={emotion recognition;human-robot interaction;multilayer perceptrons;neural net architecture;self-organising feature maps;social sciences computing;teaching;emotion expression teaching;human companion robot;deep neural architectures;neuro-inspired companion robot;NICO;hybrid deep neural network model;expression representations;convolutional neural network;CNN;self-organising map;SOM;parallel multilayer perceptron networks;MLP networks;person-specific associations;robot facial expressions;Adaptation models;Face;Light emitting diodes;Facial features;Neural networks;Human-robot interaction},doi={10.1109/IJCNN.2017.7965911},issn={2161-4407},month=may,}
Hey robot, why don’t you talk to me?
H. G. Ng, P. Anton, M. Brügger, Nikhil Churamani, and 15 more authors
In 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Aug 2017
@inproceedings{Ng2017Hey,author={Ng, H. G. and Anton, P. and Brügger, M. and Churamani, Nikhil and Fließwasser, E. and Hummel, T. and Mayer, J. and Mustafa, W. and Nguyen, T. L. C. and Nguyen, Q. and Soll, M. and Springenberg, S. and Griffiths, S. and Heinrich, S. and Navarro-Guerrero, N. and Strahl, E. and Twiefel, J. and Weber, C. and Wermter, S.},booktitle={2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN)},title={Hey robot, why don't you talk to me?},year={2017},pages={728-731},keywords={control engineering computing;face recognition;humanoid robots;human-robot interaction;intelligent robots;natural language processing;Neuro-Inspired Companion robot;user face;interaction system;natural language;personalised conversation;NICO;interaction scenario;Face;Face recognition;Natural languages;Speech;Visualization;Face detection},doi={10.1109/ROMAN.2017.8172383},issn={1944-9437},month=aug,}
The Impact of Personalisation on Human-Robot Interaction in Learning Scenarios
Nikhil Churamani, Paul Anton, Marc Brügger, Erik Fließwasser, and 15 more authors
In Proceedings of the 5th International Conference on Human Agent Interaction, Aug 2017
@inproceedings{Churamani2017TheImpact,author={Churamani, Nikhil and Anton, Paul and Br\"{u}gger, Marc and Fließwasser, Erik and Hummel, Thomas and Mayer, Julius and Mustafa, Waleed and Ng, Hwei Geok and Nguyen, Thi Linh Chi and Nguyen, Quan and Soll, Marcus and Springenberg, Sebastian and Griffiths, Sascha and Heinrich, Stefan and Navarro-Guerrero, Nicol\'{a}s and Strahl, Erik and Twiefel, Johannes and Weber, Cornelius and Wermter, Stefan},title={The Impact of Personalisation on Human-Robot Interaction in Learning Scenarios},booktitle={Proceedings of the 5th International Conference on Human Agent Interaction},series={HAI '17},year={2017},isbn={978-1-4503-5113-3},location={Bielefeld, Germany},pages={171--180},numpages={10},acmid={3125756},publisher={ACM},address={New York, NY, USA},keywords={companion robots, dialogue management, human-robot interaction, natural language understanding, person identification, person localisation, personalisation, personalised robots, social robotics, speech processing},url={http://doi.acm.org/10.1145/3125739.3125756},doi={10.1145/3125739.3125756},}
2016
iCub: Learning Emotion Expressions using Human Reward
Nikhil Churamani, Francisco Cruz, Sascha Griffiths, and Pablo Barros
In Workshop on Bio-inspired Social Robot Learning in Home Scenarios, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Aug 2016
@inproceedings{Churamani2016iCub,title={{iCub: Learning Emotion Expressions using Human Reward}},author={Churamani, Nikhil and Cruz, Francisco and Griffiths, Sascha and Barros, Pablo},booktitle={{Workshop on Bio-inspired Social Robot Learning in Home Scenarios, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}},year={2016},}
















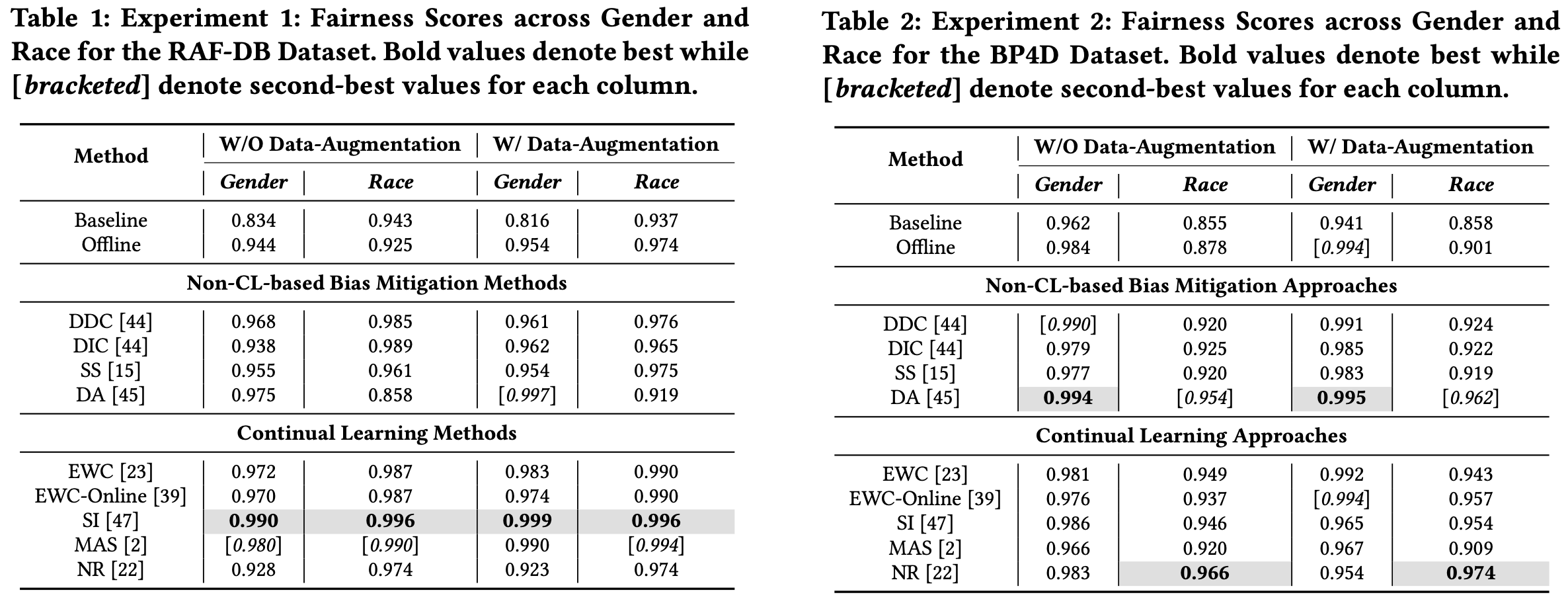 Towards Fair Affective Robotics: Continual Learning for Mitigating Bias in Facial Expression and Action Unit RecognitionIn Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 16th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2021
Towards Fair Affective Robotics: Continual Learning for Mitigating Bias in Facial Expression and Action Unit RecognitionIn Workshop on Lifelong Learning and Personalization in Long-Term Human-Robot Interaction (LEAP-HRI), 16th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2021















